Introduction to Bloom Filter

Bloom Filter is a data structure used for retrieving whether or not specific elements exist in a collection. It makes trade-offs between space/time efficiency and allowing errors.
Bloom Filter is introduced in the paper “Space/Time Trade-offs in Hash Coding with Allowable Errors (1970)” written by Burton H. Bloom. In the title of the paper, you can find keywords:
- Space/Time Trade-offs
- Hash
- Allowable Errors
It uses hash functions to check existing elements within a collection, sacrificing a degree of accuracy. It allows for collisions, the hash function’s well-known weakness.
For your information, the hash function is any function that maps data of arbitrary size to fixed-size values. Since it always returns outputs of the same size, it can occasionally produce collisions, which happen when differing input values have the same output value
How to work
The bloom filter has a very simple working principle.

Bloom filter uses a bit array of N size and one or more hash functions, and procedure of the bloom filter is as follows;
step 1. check whether the input values already exist in the collection.
step 2. hash the values using the hash function.
step 3. use a bit array to mark that the value has been received, to record in advance that the value will be used.
step 4. test whether the values exist.
Reviewing the below example will help you to understand the working flow.
Example
Let’s assume that there is a collection of blacklisted IPs, and we want to test that the incoming request IP is contained the collection. Let the bit array’s size set to 24 and use the two hash functions.

First, we should add the blacklisted IPs to the bloom filter. The bloom filter lets the values pass to parameters in hash functions.
We register the first: “192.170.0.1”
hashFunction_1("192.170.0.1") : 2
hashFunction_2("192.170.0.1") : 6The functions return 2 and 6, so the slots in the bit array marked by the indices 2 and 6 will be changed to “1” from “0.”

Again, register the other IPs: “75.245.10.1” and “10.125.22.20”
hashFunction_1("75.245.10.1") : 4
hashFunction_2("75.245.10.1") : 10The two hash functions produce numbers 4 and 10, which is to be are indices in the bit array.

hashFunction_1("10.125.22.20") : 10
hashFunction_2("10.125.22.20") : 19
Test
Now, Let’s test whether or not the incoming IP exists in the bloom filter, using the IP “75.245.10.1”.
hashFunction_1("75.245.10.1") : 4
hashFunction_2("75.245.10.1") : 10When searching for this address through the corresponding indices in the bit array,, the pointed elements are marked as “1”. So, we know this IP is present.

This time, let’s test using the IP “75.245.20.30”.
hashFunction_1("75.245.20.30") : 19
hashFunction_2("75.245.20.30") : 23The element indicated in index 19 is marked as “1”, but the element in case index 23 is not “1”.

This means that the IP is not included as an element of the blacklisted IP collection, so you can notice the IP “75.245.20.30” is not blacklisted.
At last, let’s test the case when the IP is “101.125.20.22”.
hashFunction_1("101.125.20.22") : 19
hashFunction_2("101.125.20.22") : 2The two functions produce the results each 19 and 2. When inspecting two numbers as indices in a bit array, we know the two pointed elements represent 1.

However, the IP is not contained within the collection; this is a false positive, which occurs when the function incorrectly reports a positive outcome.
As seen in this example, the Bloom Filter may cause false positives; however, it is widely used since it is known to have the properties of speed and space-efficiency.
Collision in Hash Function
Collision in a hash function is well known as a characteristic of the hash function , and it occurs when input data hashes by a particular hash function are assigned to the same slot in a data structure such as hash table.
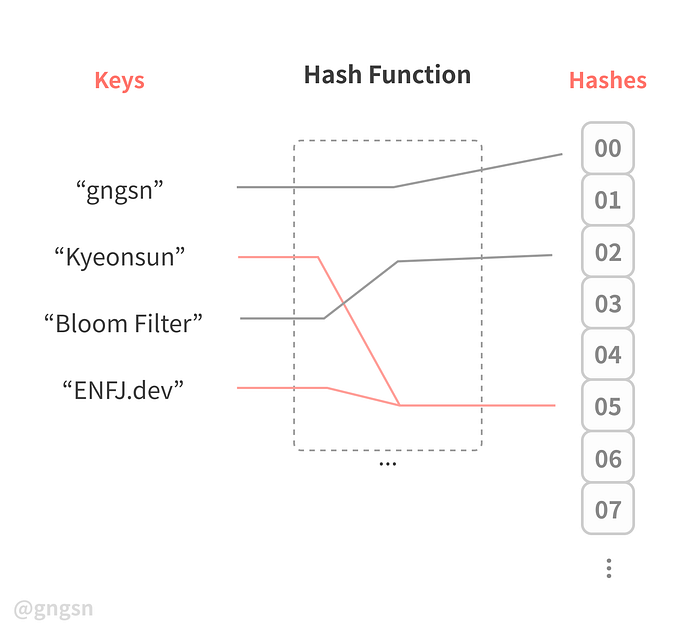
Because of this characteristic of hash functions, the Bloom Filter can occur some errors that return a wrong judgment: False Positive.
False Positive Probability
The Bloom Filter has a possibility of False Positive, which judges non-existing elements to exist. The FPP (False Positive Probability) can be evaluated mathematically.
In the captured site below , you can calculate the FPP easily.

n: Number of items in the filter
p: Probability of false positive. fraction between 0 and 1
m: Number of bits in the filter
k: Number of hash functions
Hash Table VS Bloom Filter
If you are interested in data structures or have even a little programming experience, you might know the hash table.
The hash table is used for accessing the specific entries very quickly using the keys given as parameters. For instance, the Dictionary in Python and the HashTable class in Java are both implementations of the hash table.
The bloom filter is a space-efficient probabilistic data structure that is used to test whether the given elements contain a collection. It just checks whether or not the element exists by examining the bit set filled by 1.
A summary of the difference between the hash table and Bloom Filter is listed below.
✔️ Store Object
A Hash table saves a value corresponding to a given key.
A Bloom Filter does not save the associated values, because the Bloom Filter just returns whether or not the key exists.
✔️ Space Efficiency
A Hash table has a little space efficiency. The Bloom Filter has more space efficiency because stored values could be smaller than the origin.
✔️ Deletion
A Hash table is able to remove elements.
The Bloom Filter is unable to remove elements.
✔️ Accuracy
A Hash table supports accuracy values mapping a key.
The Bloom filter could return wrong values because the filter has a nonzero probability of false positives.
✔️ Collision
A Hash table has to implement multiple hash functions or get a strong hash function to minimize a collision.
The Bloom filter does not need to process the collision because it already uses many hash functions.
✔️ Application
Hash table is used in compiler operations, program languages (hash table based data structure), password verification, etc. [short for et cetera]
Bloom filter is used in network routers, web browsers (for detection of malicious urls), password checkers (to find weak, guessable, or forbidden passwords), etc.
How to use in Java
First of all, you should append the dependency.
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>The usage of bloom filter is as below.
public class BloomFilterTests {
@Test
public void stringTest() {
BloomFilter<String> blackListedIps = BloomFilter.create(
Funnels.stringFunnel(Charset.forName("UTF-8")), 10000, 0.005);
blackListedIps.put("192.170.0.1");
blackListedIps.put("75.245.10.1");
blackListedIps.put("10.125.22.20");
Assertions.assertTrue(blackListedIps.mightContain("75.245.10.1"));
}
}









