The Evolution of Architecture from ETL to EtLT

Written by Gao Jun, Apache SeaTunnel(Incubating) PPMC, Apache DolphinScheduler PMC, Trino contributor,Apache Arrow-DataFusion contributor
For a better understanding, let’s first introduce the evolution of the data warehouse architecture from ETL to EtLT.
Looking back on the past, we will find that the entire data warehouse was using an ETL architecture from 1990 to 2015, under which the data source is mainly structured data, such as MySQL, SQL, Server, Oracle, ERP, CRM, etc. At the same time, data warehouse computing is mainly undertaken by Oracle and DB2 in the OLTP era, which are databases used for querying and storing historical data. In this era, the computing power of databases such as Oracle and DB2 is still relatively weak, and it is difficult to meet the requirements of data warehouse computing tasks in all scenarios.

In this process, professional ETL software such as Information, Talend, and Kettle was born. Many companies are still using this software. With the emergence of new technologies, like MPP technology, and the popularity of distributed architecture technologies, such as Hadoop, Hive, etc., people discover that it is possible to use very low-cost Hardware, instead of these expensive Oracle, and DB hardware services. These technologies mark that we have entered the era of ELT.

The core feature of this era is that data from different data sources, including structured and unstructured data, logs, etc., can be loaded into the data warehouse without any processing, or after some simple standardization, such as cleaning, word count reduction, etc, and was calculated layer by layer by engines such as MapReduce and Spark. At this time, because the data sources are not so complicated, people handle the process from data sources to data warehouses, mainly by writing MR programs or writing Spark programs.

As data sources grow more and more complex, many new technologies continue to emerge, and data sources are more complex. Some SaaS services and cloud data storage have appeared, further making data sources more complex. At the same time, on the target side, the data warehouse is very different from the previous data warehouse. With the emergence of a data lake and real-time data warehouse technology, the target side of data integration is also more complicated. At this time, if the MR program is still developed by data engineers as before, the integration efficiency will be very low. At this time, some professional teams and professional tools are urgently needed to solve such an ELT process.
Thus, the field of data integration was born. Apache SeaTunnel is the platform for next-generation data integration.
In the ELT scenario, there is a concept called EtLT. The small t there is different from the uppercase T in the back, which means data standardization, such as field screening, structured conversion of unstructured data, etc. It does not involve join, or aggregation. We also split the personnel under these two systems. The data EL process, that is, the previous EtL process is mainly handled by data engineers who do not need to understand the business very well. They only need to understand the relationship between different data sources, and the data characteristics and differences between them. After the data is loaded into the data warehouse, professional AI data scientists, data analysts, SQL developers, and other business-savvy people will do calculations based on the original data.
This is the evolution from ETL to EtLT architecture. In 2020, James Densmore proposed the EtLT architecture in the book “Data Pipelines Pocket Reference”. He predicted that from 2020 to the future, this is the evolution trend of architecture.
Pain points in the field of data integration & common solutions
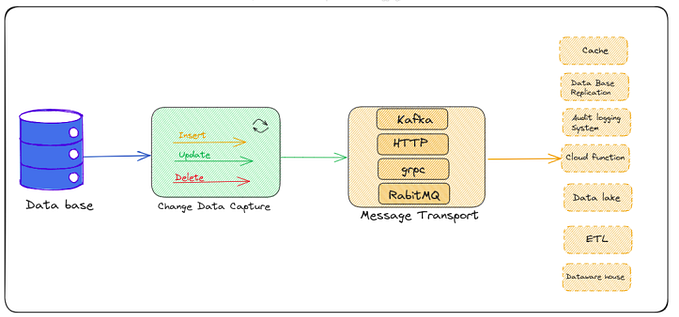
From this, we extend to some common pain points and solutions in the field of data integration. picture
I found some core pain points in the field of data integration in the previous technology exploration, including:
- Too many data sources. The Apache SeaTunnel community currently counts nearly 500 data sources and is still growing rapidly; With the iteration of data source versions, there will be problems in compatibility, and with the continuous emergence of new technologies, we need to quickly adapt to data sources in the field of data integration, which is a core pain point that needs to be solved;
- Complex sync scenarios: data synchronization includes offline, real-time, full, incremental synchronization, CDC, multi-table synchronization, etc. The core requirement of the CDC is to solve the problem of directly reading and analyzing the change log of the database, and applying it downstream. During this process, many scenarios, such as how to parse the log data format of different databases, transaction processing, synchronization of the whole database, sub-database and sub-table, etc., need to be adapted and supported;
- How to monitor the process and how to quantify the indicators: the lack of monitoring during the synchronization process will lead to information opacity, such as uncertainty about the amount of data that has been synchronized;
- How to achieve high throughput and low latency under limited resources to reduce costs;
- How to reduce the impact on the data source: When multiple tables need to be synchronized in real-time, frequent reading of the binlog will put a lot of pressure on the data source and affect its stability of the data source. At the same time, when there are too many JDBC connections, the data source will be unstable, and even if the data source limits the maximum number of connections, the synchronization job may not run normally. The data integration platform needs to minimize the impact on the data source, such as reducing the connection occupation and limiting the synchronization speed.
- How to achieve data consistency, no loss, and no duplication: Some systems with high data consistency requirements do not allow data loss and duplication.
To meet these needs, we need a data integration product that is easy to use, easy to expand, easy to manage, and easy to maintain. We did scheme research for this.
We found that different data integration products are mostly aimed at the following scenarios:
- Full offline increment
In this scenario, Sqoop was widely used in the early days. It was also a project under the Apache Foundation, but its core problem is that it supports few data sources and relies on the MapReduce architecture, which is very slow. And it has been decommissioned from Apache, which belongs to the previous generation of data integration projects.
At present, DataX is also popular. This is a very useful data synchronization tool, but the problem is that its open-source version does not support real-time synchronization, so it cannot support multi-level parallel processing. And because there is no distributed snapshot algorithm in the internal design, data consistency cannot be guaranteed, and breakpoint resumes cannot be supported.
2. Real-time synchronization
In real-time scenarios, Flink and Spark Streaming are widely used. However, since these two products are positioned as computing engines, their core capabilities are more about processing complex data calculations, and it is difficult to support enough data sources like a professional data synchronization product. Moreover, the fault tolerance of the two is relatively large by design, which will cause the synchronization of one table to fail when performing multi-table synchronization, and the entire job needs to be stopped and re-executed. And in some cases, you need to write Flink and Spark code, and there are learning costs.
3. CDC scenario
For the CDC scenario, currently, people use Flink CDC more often, but the problem is that its bottom layer is still Flink and inherits the problems of Flink, and it does not support table structure changes and a single Source reads multiple tables (each Source Only one table can be read, which means that when CDC is synchronizing, the number of JDBC connections to be used is equal to the number of tables).
To sum up, in the data integration scenario, if the user wants to support all scenarios, these three components need to be used. The overall architecture will be very complicated, and the company needs to have a big data platform, and the learning cost is also quite high in different scenarios. In addition, different code management is also difficult.
Apache SeaTunnel, the next-generation data integration platform, can solve these pain points.
Next-generation data integration platform Apache SeaTunnel
6 Design Goals
Apache SeaTunnel’s design goals are mainly summarized into six. The first is that it must be simple and easy to use, and can start a synchronization job with very little configuration and some simple commands.
The second point is that it must be able to monitor the synchronization process, and the indicators must be quantifiable so that users can know the status of the current synchronization operation, and it cannot be a black box.
The third is to have rich data source support. The community has counted more than 500 data sources. At present, the community has supported more than 100, and the data source support is growing rapidly. It increases by forty or fifty new data sources in one quarter.
The fourth is very important to support all scenarios, such as real-time synchronization, offline synchronization, the incremental full amount, CDC, multi-table synchronization, and other scenarios, without requiring users to use various tools to combine.
The fifth is to solve the problem of data consistency, to ensure that those systems with high data consistency requirements can not lose data, and the data is also repeated.
Finally, in terms of performance, we need to consider how to reduce resource usage and impact on data sources based on satisfying these functions.
Project development history

Here is also a brief talk about the development of the Apache SeaTunnel project. This project was open-sourced in 2017. It was called Waterdrop at the time. Some companies may have used the OPPO version in the early days. We contributed to the Apache Foundation in December 2021 and passed it unanimously. After three months, we released the first Apache SeaTunnel version in March 2022 and completed a major version refactoring in October. The main effect of refactoring is that it can support the operation of multiple engines, the entire design of the engine has been refactored, and the scalability is better. In November, we released Apache SeaTunnel Zeta, an engine dedicated to data integration. In December, we supported CDC connectors, and the number of connectors exceeded 100. This year, we will soon release a new version that can support higher versions of Flink and Spark, and Zeta Engine will support features such as multi-table synchronization and table structure changes.
Users all over the world
The Apache SeaTunnel community currently has nearly 5,000 members, with more than 200 contributors in the community, and the speed of PR submission and merging is relatively fast. In addition, our users cover domestic Internet companies, such as Station B, Tencent Cloud, and others. Overseas, Shopee, India’s second-largest telecom operator, Bharti Telecom, etc. is also using Apache SeaTunnel.
Core Design and Architecture
Overall structure

The Apache SeaTunnel architecture is mainly divided into three modules. The first one is the data source, which includes some domestic and foreign databases; the second part is the target end. The target end and the data source can be combined. They are called data sources, which are mainly databases. , SaaS services, and product components such as data lakes and warehouses. From the data source to the target, we have defined a set of APIs dedicated to data synchronization, which is decoupled from the engine and can theoretically be extended to many engines. The engines we currently support include Apache SeaTunnel Zeta, Flink, and Spark.
Connector API decoupled from the engine
The core of this set of API designs is decoupling from the engine, specifically for data integration scenarios, divided into Source API, and Transform API, which is the small t, sink API, and CDC API we mentioned before. Translating with the help of the Translation API allows these connectors to execute on different engines.
In all engines, the connector API is based on the checkpoint mechanism. The core goal is to integrate distributed snapshot algorithms in different engines and apply the checkpoint capability of the underlying engine to implement features such as two-phase commit to ensure data consistency.
Source Connector

Based on this set of APIs, we implemented the Source connector. Taking the JDBC connector as an example, it supports both offline and real-time operation modes. For the same connector, you only need to specify the job. mode as BATCH or STREAMING in the env configuration You can easily switch between offline and real-time synchronization modes.
The main capabilities provided by the Source connector include parallel reading, dynamic discovery of shards, field projection, and Exactly-once semantic guarantee. The bottom layer uses the checkpoint capability provided by the engine, and the Source API supports the underlying engine to call the checkpointed API to ensure synchronization. Data will be preserved and duplicated.
Sink Connector
The main features supported by Sink Connector include:
- SaveMode support, flexible selection of target performance data processing methods
- Automatic table creation, support for table creation template modification, hands-free in multi-table synchronization scenarios
- Exactly-once semantic support, data will not be lost or repeated, CheckPoint can adapt to Zeta, Spark, Flink three engines
- CDC support, support for processing database log events
Transform Connector

Key features of the Transform Connector include:
- Support for copying a column to a new column
- Support field rename, change order, type modification, delete column
- Support for replacing content in data
- Support for splitting a column into multiple columns
- CDC Connector Design

CDC Connector mainly has the following functions:
- Support lock-free parallel snapshot history data
- Support dynamic table addition
- Support sub-database sub-table and multi-structure table reading
- Support Schema evolution
- Support the Checkpoint process to ensure that data is not lost or repeated
- Support offline batch CDC synchronization
Checkpoint function design

Finally, it should be emphasized that all Apache SeaTunnel Connectors are designed based on checkpoint logic. The job starts from the Split enumerator, enters the Source reader, sends the data to the Sink Writer after reading, and finally submits it by the AggregateCommitter.
Next-generation data integration engine Apache SeaTunnel Zeta
Apache SeaTunnel Zeta, the next-generation data integration engine, is positioned as an easy-to-use, dedicated engine for full-scenario data integration, and based on this, it is faster, more stable, and more resource-efficient.
Apache SeaTunnel Zeta cluster management
The cluster management method of Apache SeaTunnel Zeta is characterized by: • No need to rely on three-party components, no need to rely on big data platforms
- Unowned (optional master)
- WAL, a full cluster restart can also restore previously running jobs
- Support distributed snapshot algorithm to ensure data consistency
Next, I will introduce some of the proprietary attributes of the Apache SeaTunnel Zeta engine and what core problems it solves.
Apache SeaTunnel Zeta Pipeline Base Failover

- For Batch jobs and streaming jobs, resource allocation is performed in units of the Pipeline, and the Pipeline can start executing after allocating the required resources without waiting for all tasks to obtain resources. This can solve some pain points in data synchronization of engines such as Flink, that is, when there are multiple Sources and Sinks in a job for synchronization, if there is a problem at any end, the entire job will be marked as failed, and stopped.
- Fault tolerance (Checkpoint, state rollback) is implemented at the granularity of the Pipeline. When a problem occurs in the target table, it will only affect the upstream and downstream tasks, and other tasks will be executed normally.
After the problem is solved, manual restoration of a single Pipeline is supported.
Apache SeaTunnel Zeta Dynamic Thread Sharing

The core of dynamic threads is to reduce the problem of CDC multi-table synchronization, especially in scenarios where a large number of small tables exist, due to limited resources and many threads, resulting in performance degradation. Dynamic threads can dynamically match threads according to running time and data volume, saving resources. After testing, and running a job with 500 small tables in a single JVM scenario, the performance can be improved by more than 2 times after dynamic threads are enabled.
Apache SeaTunnel Zeta Connection Pool Sharing

Connection pool sharing is mainly used to solve the scenarios occupied by a large number of JDBCs, such as a single very large table, there are many parallel tasks to process, offline synchronization of multiple tables, CDC synchronization of multiple tables, etc. Connection pool sharing allows the same Job on the same TaskExecutionService node to share JDBC connections, thereby reducing JDBC usage.
Apache SeaTunnel Zeta multi-table synchronization

The last is multi-table synchronization, which is mainly used for table partition transform processing after the CDC Source is read, and the data is distributed to different Sinks, and each Sink will process the data of one table. In this process, connector sharing is used to reduce the usage of JDBC connections, and dynamic thread sharing is used to reduce thread usage, thereby improving performance.
Performance comparison
We conducted performance tests, mainly including the performance of Apache SeaTunnel in local environments such as MySQL data synchronization to Hive, and MySQL synchronization to S3 cloud test environments.
Test environment:
Local test scenarios: MySQL-Hive, Postgres-Hive, SQLServer-Hive, Orache-Hive
Cloud test scenario: MySQL-S3 Number of
Columns: 32, basically including most data types
Lines: 3000w lines
Hive file text format 18G
Test node: 1, 8C16G
Result:
Local Test: Apache SeaTunnel Zeta VS DataX
SeaTunnel Zeta syncs data around 30–50% faster than DataX.
Memory has no significant impact on SeaTunnel Zeta’s performance.
Cloud data synchronization: The performance of Apache SeaTunnel in MySQL to S3 scenarios is more than 30 times that of Airbyte and 2 to 5 times that of AWS DMS and Glue.
It can be seen that Apache SeaTunnel can complete synchronization in a small memory, and it is still in the case of a single point. Because Zeta supports distributed, it is believed that Apache SeaTunnel will have better performance when the order of magnitude is larger and multi-machine parallelism.
Recent Planning
Apache SeaTunnel plans to support some new features soon, including:
- Spark3 support
- Flink15, 16 support
- Schema evolution
- Multi-table synchronization …
If you are interested in our work, welcome to join the Apache SeaTunnel community!
📌📌Welcome to fill out this survey to give your feedback on your user experience or just your ideas about Apache SeaTunnel:)